大数据学习路线指南
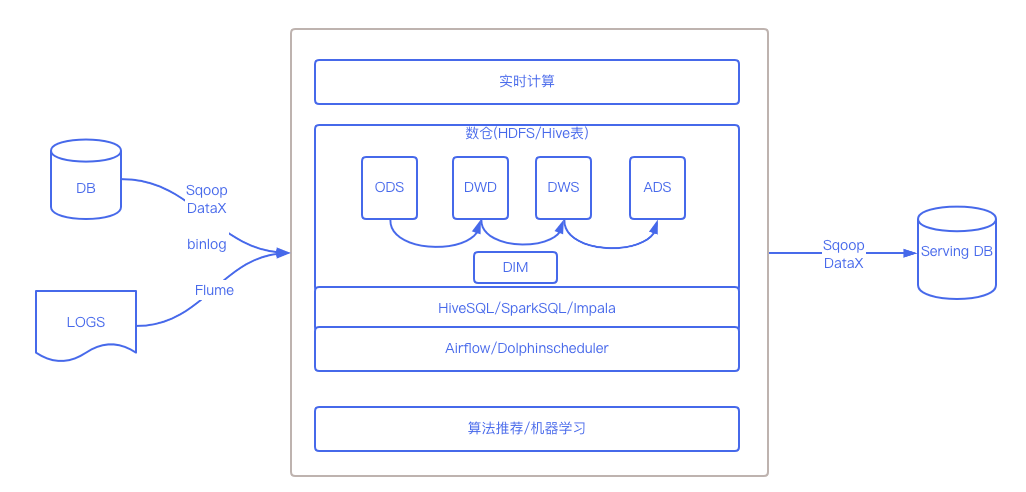
下图是一个简化的大数据处理流程,主要分为了数据采集、数据计算、数据再利用这三个大的环节,本文将针对每个环节进行详细阐述,主要包括技术实现细节,运用到的组件介绍等。
linux
如果你之前没有 linux 基础,一定要把 Linux 的知识学习一遍,这对后续的学习非常非常重要,我强烈推荐你学习《Linux就该这么学》,在线阅读地址 https://www.linuxprobe.com/basic-learning-00.html ,当年我上大学那会儿不知道有个教程,后来才发现了它,它现在已经出版成书了。分享一下我当年看的 itercast 的视频教程,虽然好几年过去了,但是任然不会过时, 链接: https://pan.baidu.com/s/1O9NqhUV9qUwnGaPDI0gEjA?pwd=k5wh 提取码: k5wh
需要掌握基于 Linux 系统下的常用命令和常见问题诊断。
- 基本命令
- 系统、网络、磁盘管理
- 权限模型
- 基础的 Shell 脚本
编程语言
大数据中主要包括 Java Scala Python 三种语言:
- Java 是大数据领域的主要语言,百分之90的大数据生态组件都是基于Java开发的,学好 Java 有助于在优化性能、排查问题方面得心应手,对Java的要求没有上限,越熟悉越好。
- Scala 是最强大的计算引擎 Spark、最强的消息队列Kafka的开发语言,如果我们要写 Spark ,Scala是必不可少的。
- Python 更像一把锋利的匕首,用来写各种脚本,各种临时任务等等,同时它也是数据分析、机器学习的必备语言
数据同步ETL
主要是将业务数据库(MySQL、postgress等)、应用日志同步到大数据集群,包括增量、全量同步,目前使用比较多的同步工具:
- Sqoop 比较老牌的同步工具,官网不在更新,但是还是有非常多的用户量的。
- DataX 是阿里云DataWorks数据集成的开源版本。
- SeaTunnel 目前比较火的同步工具,它主打易用、高性能、分布式、实时同步等。
- Flume 日志同步工具,可用于同步nginx日志。
- flink-cdc等通过binlog方式同步业务数据库,也可以自己编写同步逻辑。
离线计算
Hadoop 体系是学习大数据框架的基础,尤其是 MapReduce、HDFS、Yarn 基本垫定了整个数据方向的发展道路,也是后面我们学习其他框架的基础。
- MapReduce:掌握 MapReduce 的工作原理,能手写WordCount程序,解决数据倾斜问题,掌握 map 和 reduce 的完整流程。
- HDFS:掌握常用hdfs常用命令,熟悉DataNode和NameNode的基本原理,写数据、读数据的完整流程等等。
- Yarn:资源池的划分,资源调度策略,它是整个集群的计算资源管理这
- Spark:离线计算的必用组件,掌握spark-sql,Spark 的 rdd 编程,spark常用算子,shuffle 等原理。
- Hive:目前Hive的默认引擎MapReduce速度已经跟不上了,我们通常使用 Hive on spark 来提升速度,或者直接创建Hive表,使用 spark 或 其他引擎直接写入 hdfs 目录
- Impala: 虽然它的查询速度很快,但我把它归结到了离线计算,因为它的稳定性没有业务数据库那么高。
实时计算
主要包括 Spark Streaming、Flink
- Spark Streaming:它是微批处理,我们可以控制处理一个批次的时间间隔,在实时性要求不高的场景可以使用。
- Flink: 热度非常高的实时计算框架,基于事件驱动数据流,同时其周边生态也非常丰富。
数仓建模
数仓建模是一个理论加实践的过程,通常以维度建模为指导,将数据分层,这里分层是指,我们的数据存储在Hive表中,每个表都处于某一个层中,常见的分层:
- 数据运营层:ODS(Operational Data Store)
- 数据仓库层:DW(Data Warehouse)包括DWD、DWS层
- 数据应用层:ADS(Application)
- 维表层:DIM(Dimension)
分层的目的:
- 清晰数据结构:每一个数据分层都有它的作用域和职责,在使用表的时候能更方便地定位和理解
- 减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算
- 统一数据口径:通过数据分层,提供统一的数据出口,统一对外输出的数据口径
- 复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层解决特定的问题
数据可视化
数据可视化通常是将 ADS 层的数据实时或离线的方式展示出来,通常使用的工具有:tableau、superset、redash、Metabase等等
元数据管理
元数据管理包括了数据仓库中的表依赖关系、表的详细信息、表的数据信息等等,常用的开源组件有 datahub、atlas。
一个好的元数据管理平台,可以帮助我们更好的梳理表的依赖关系、减少数据的使用成本。
推荐算法
- 常见的大数据领域的算法:倒排、TopN、布隆过滤、字典树等
- 了解常见的机器学习算法
- 了解算法工程化
任务调度
任务调度是是一个非常重要的环境,上面的各个组件可以配合使用,他们最终都会被任务调度系统管理起来,常用的调度系统有
- DolphinScheduler:目前github star 10.8k,国内开发团队,易用性很高,上手容易。
- Apache Airflow:目前github star 31k,功能强大,上手稍微难一点,但是上手后爱不释手,自定义功能非常强大,本站有airflow相关的使用总结,详情站内搜索 airflow 关键字查看详情。
参考资料