Hbase 性能优化总结
·
4 min read
Region预分区
避免自动分区产生的性能消耗、负载均衡请求
RowKey合理设计
HBase通过rowkey、family、qualifier、TimeStamp可以对HBase中的数据进行快速定位,HBase中rowkey可以唯一标识一行记录。
Rowkey长度原则
建议是越短越好,不要超过16个字节,建议设计在10~100个字节之间,原因如下:
- 数据的持久化文件HFile中是按照KeyValue存储的,KeyValue越大,越影响HFile的存储效率。如果Rowkey为100个字节,1000万列数据光Rowkey就要占用100*1000万=10亿个字节,将近1G数据。
- MemStore将缓存部分数据到内存,如果Rowkey字段过长内存的有效利用率会降低,系统将无法缓存更多的数据。
- 目前操作系统是都是64位系统,内存8字节对齐。控制在16个字节,8字节的整数倍利用操作系统的最佳特性。
Rowkey散列原则
目的是为了不造成热点问题:
- 建议将Rowkey的高位作为散列字段,比如RowKey的后面部分的hash值作为RowKey的前面部分。
- 建表时使用预分区,创建指定的个数的分区,以及每个分区的startKey和EndKey,在写入数据时按照startKey和endKey写入。
Rowkey唯一原则
必须在设计上保证其唯一性,rowkey是按照字典顺序排序存储的
Scan优化
除了使用Get外,可以使用 Scan 批量获取数据。
- scan可以通过setCaching与setBatch方法提高速度(以空间换时间)
- scan可以通过setStartRow与setEndRow来限定范围。范围越小,性能越高。
- scan可以通过setFilter方法添加过滤器
setCaching 与 setBatch
- setCaching设置一次客户端与regionserver的RPC请求可以获取多少行数据。对于缓存操作,如果行的数据量非常大,多行数据有可能超过客户端进程的内存容量,由此引入setBatch解决方案。
- setBatch 设置一个RowKey一次装载多少cell,setBatch可以让用户选择每一次ResultScanner实例的next操作要取出多少cell,例如,在扫描中设置setBatch(5),则一次next()返回的Result实例会包括5列。如果一行包括的列数超过了批量中设置的值,则可以将这一行分片返回。Batch参数决定了一行数据分为几个Result,它只针对一行数据,Batch再大,也只能将一行的数据放入一个Result中。所以当一行数据有10列,而Batch为100时,也只能将一行的所有列都放入一个Result,不会混合其他行;
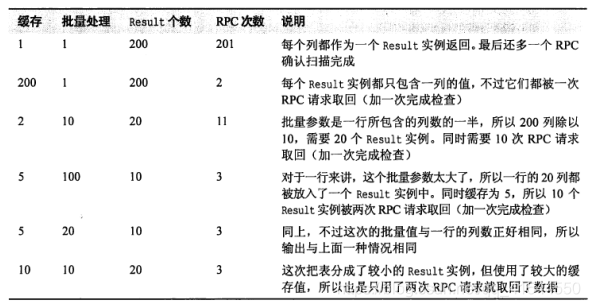
- 假如我们建立了一张表:10行数据,有2个列族,每个列族下有10列,这意味着整个表一共有200列(cell)。
RPC请求次数 = (总行数 * 每行cell数) / min(每行cell数,Batch) / Caching
列族不易太多
一张表最多2~3个。
因为一个cf会对应一个store,每个store都有一个Memstore,当触发flush阈值后进行flush的最小单位是Region,而不是MemStore级别的,所以会有多个cf被flush,会生成多个HFile文件。并且HFile多了就会频繁触发compact。最终导致系统产生更多的I/O。
批量数据写入采用BulkLoad
批量数据写入采用 BulkLoad
开启BloomFilter
BloomFilter 是列族级别的过滤
增大处理请求的线程数
hbase-site.xml
属性名:hbase.regionserver.handler.count
属性值:30
可以根据客户端的请求数进行调整,读写请求较多时,增加此值,协处理器大量计算时也需要增加次参数。
memstore刷写
属性:hbase.hregion.memstore.flush.size
合理的memstore刷写HFile阈值,默认128M
减少RegionServer的region数量
如果一个RegionServer上的Region过多会很容易达到RegionServer级别的触发条件,进行flush的MemStore也会较小,从而生成了过多的小的HFile文件,而HFile过多就会触发compact。
- 参考资料