HBase Shell 命令使用总结
一. 概要说明
- HBase的名字的来源于Hadoop database,即hadoop数据库,不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库,而且它是基于列的而不是基于行的模式。
- HBase shell是HBase的一套命令行工具,类似传统数据中的sql概念,可以使用shell命令来查询HBase中数据的详细情况。安装完HBase之后,如果配置了HBase的环境变量,只要在shell中执行hbase shell就可以进入命令行界面。
二. HBase表结构

2.1 行键Row Key
与NOSQL数据库们一样,Row Key是用来检索记录的主键。访问HBase table中的行只有三种方式:通过单个Row Key访问、通过Row Key的range、通过全表扫描。Row Key行键可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100bytes),在hbase内部,Row Key保存为字节数组。存储时,数据按照Row Key的字典序排序存储。
不论一次读写多少列,行的一次读写都是原子操作,这个设计决策能够使用户很容易的理解程序在对同一个行进行并发更新操作时的行为。HBase不支持条件查询和order by等查询。
2.2 列族Column Family
hbase表中的每个列,都归属与某个列族。列族是表schema的一部分(而列不是),必须在使用表之前定义。列名都以列族作为前缀。例如courses:history ,courses:math 都属于courses 这个列族。访问控制、磁盘和内存的使用统计都是在列族层面进行的。实际应用中,列族上的控制权限能帮助我们管理不同类型的应用:我们允许一些应用可以添加新的基本数据、一些应用可以浏览基本数据、一些应用则只允许浏览部分数据。
2.3 时间戳 Timestamp
HBase中通过 row 和 column 确定的为一个存贮单元称为 cell。每个 cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由 hbase 在数据写入时自动赋值,此时时间戳是精确到毫秒的系统当前时间,时间戳也可以由客户端显示赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个 cell 中,不同版本的数据按照时间倒序排序,最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,hbase提供了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段时间内的版本,比如最近七天。
2.4 单元 Cell
Cell是由 {row key, column, version} 唯一确定的单元。Cell中的数据是没有类型的,全部是字节码形式存贮。
cell:单元格,由五元组(row,column,timestamp,type,value)组成的结构,其中type表示Put/Delete这样的操作类型,timestamp代表这个cell的版本。这个结构在数据库中实际是以KV结构存储的,其中(row,column,timestamp,type)是K,value字段对应KV结构的V。
三. 常用操作
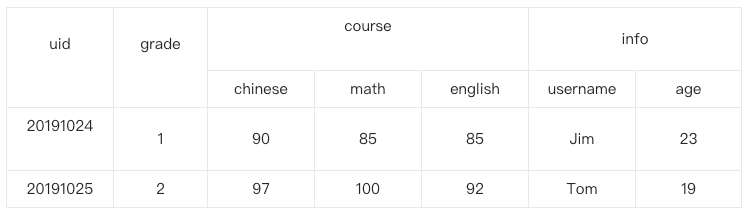
上表是一张学生成绩单,其中,uid 是行键,grade 是一个特殊列族,只有一列并且没有名字(列族下面的列是可以没有名字的),course 是一个列族,由 3 个列组成(Chinese、math 和 english)。用户可以根据需要在 course 中建立更多的列,如 computing、physics 等。同理info列族下面有username、age两个列。
3.1 普通操作
# 查询服务器状态
hbase(main):002:0>status
1activemaster,0backupmasters,3servers,0dead,50.6667averageload
Took0.4686seconds
# 查询版本号
hbase(main):003:0>version
2.0.2.3.1.4.0-315,r,FriAug2305:15:48UTC2019
Took0.0004seconds3.2 DDL操作
DDL操作主要用来定义、修改和查询表的数据库模式。
# 创建一个表,注意:列族只能在首次创建表的时候确定,不能后期新增列族
hbase(main):004:0>create 'student','grade','course','info'
# 列出所有表
hbase(main):005:0>list
# 获取表的描述
hbase(main):010:0>describe 'student'
# 删除一个列族
hbase(main):011:0>alter 'student',{NAME=>'info',METHOD=>'delete'}
# 禁用启用表
hbase(main):018:0>enable 'student'
hbase(main):013:0>disable 'student'
hbase(main):017:0>is_enabled 'student'
# 删除表
hbase(main):013:0>disable 'student'
hbase(main):013:0>drop 'student'
hbase(main):002:0>exists 'student'
3.3 DML操作
DML操作主要用来对表的数据进行添加、修改、获取、删除和查询。
# 创建表格,列族里边可以自由添加子列。如果列族下没有子列,则只加“:”即可。
hbase(main):017:0>create 'student','grade','course','info'
# 插入数据
put 'student','20191024','grade:','1'
put 'student','20191024','course:Chinese','90'
put 'student','20191024','course:math','85'
put 'student','20191024','course:english','85'
put 'student','20191024','info:username','Jim'
put 'student','20191024','info:age','23'
put 'student','20191025','grade:','2'
put 'student','20191025','course:Chinese','97'
put 'student','20191025','course:math','100'
put 'student','20191025','course:english','92'
put 'student','20191025','info:username','Tom'
put 'student','20191025','info:age','19'
# 获取指定行。
get 'student','20191024'
# 获取指定行的指定列族。
get 'student','20191024','course'
# 获取指定行的指定列族指定列。
get 'student','20191024','course','course:english'
# 根据时间戳获取。同一个值有不同的版本,可以据不同的时间戳获取不同版本的数据。
get 'student','20191024',{COLUMN=>'course:Chinese',TIMESTAMP=>1571920764551}
# 全表扫描。
scan 'student'
# 为了限制返回的结果,用户可以指定一些修饰词,如TIMERANGE、FILTER、LIMIT、STARTROW、STOPROW、TIMESTAMP、MAXLENGTH或COLUMN。
# 只获取english的成绩。
scan 'student',{COLUMN=>'course:english'}
# 统计表的总行数
count 'student'
# 更新一条记录,更新一条记录也就是重新赋值一遍。
put 'student','20191024','course:Chinese','99'
# 删除指定行
deleteall 'student','20191024'
# 删除指定行的指定列
delete 'student','20191024','info:age'
# 清空整张表,会删除所有的region,只保留一个,慎用!!!
truncate 'student'删除表的所有行的数据,只能使用api的方式。
/**
* 删除指定表的所有行数据
*/
public static void deleteAllRows() throws Exception {
HashSet<String> willBeDeleted = new HashSet<String>() {{
add("bitmap_attribute");
add("wide_userprofile");
}};
HBaseClient hBaseClient = new HBaseClient(HbaseConfigs.createHBaseConfig());
Admin admin = hBaseClient.conn.getAdmin();
HTableDescriptor[] tableDescriptor = admin.listTables();
for (HTableDescriptor tableDesc : tableDescriptor) {
String tableName = tableDesc.getNameAsString();
if (willBeDeleted.contains(tableName)) {
Table table = hBaseClient.conn.getTable(TableName.valueOf(tableName));
List<Delete> deleteList = new ArrayList<Delete>();
Scan scan = new Scan();
ResultScanner scanner = table.getScanner(scan);
for (Result r : scanner) {
deleteList.add(new Delete(r.getRow()));
}
scanner.close();
try {
table.delete(deleteList);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}四. 查询数据用法
4.1 get
get 用于获取指定的行,而且返回的内容只包含一行。get后面跟着表名和row key,在后面可以跟一个字典来控制这一行中的指定列或者指定版本。
# 获取指定行。如果某些列有多版本,默认取最新的版本。
get 'student','20191024'
# 获取指定行的指定列族。
get 'student','20191024','course'
# 获取指定行的指定列族的指定列,方法一。
get 'student','20191024','course:english'
# 获取指定行的指定列族的指定列,方法二。
get 'student','20191024','course','course:english'
# 获取指定行的指定列族的指定列的指定时间戳版本。
get 'student','20191024',{COLUMN=>'course:english',TIMESTAMP=>1571970726273}
4.2 scan
scan 用于扫描表中的数据。
# scan。获取所有行
scan 'student'
# LIMIT。获取指定的行数。或许的scan中都可以加入限制条件LIMIT
scan 'student',{LIMIT=>1}
# COLUMNS。获取所有行的指定一个列族、多个列族
scan 'student',{COLUMNS=>'course'}
scan 'student',{COLUMNS=>['course','info']}
# COLUMNS。获取所有行的指定一列、多列。
scan 'student',{COLUMNS=>'course:english'}
scan 'student',{COLUMNS=>['course:english','course:math']}
# TIMERANGE。查找指定时间范围
scan 'student',{TIMERANGE=>[1,1571971201798]}
# STARTROW ENDROW。行键的字典排序范围,比如'10'小于'2'。包括STARTROW本身,不包括ENDROW本身
scan 'student',{STARTROW=>'20191024',ENDROW=>'20191025'}
# FILTER。行键前缀过滤。
scan 'student',{FILTER=>"PrefixFilter('20191024')"}
# FILTER。行键字符串包含过滤器
scan 'student',{FILTER=>"RowFilter(=,'substring:25')"}
# FILTER。行键正则匹配过滤器
scan 'student',{FILTER => "RowFilter(=, 'regexstring:.*24$')"}
# FILTER。列名前缀过滤器
scan 'student',{FILTER=>"ColumnPrefixFilter('e')"}
# FILTER。多个列名前缀过滤器
scan 'student',{FILTER=>"MultipleColumnPrefixFilter('e','m')"}
# FILTER。列值过滤器,需要导入类。获取info:username等于Jim的列。
importorg.apache.hadoop.hbase.filter.SingleColumnValueFilter
importorg.apache.hadoop.hbase.filter.CompareFilter
scan'student',{FILTER=>SingleColumnValueFilter.new(
Bytes.toBytes('info'), #列族
Bytes.toBytes('username'), #字段
CompareFilter::CompareOp.valueOf('EQUAL'),#比较运算符
Bytes.toBytes('Jim')) #值
}
(1)比较运算符
EQUAL 相等
GREATER 大于
GREATER_OR_EQUAL 大于等于
LESS 小于
LESS_OR_EQUAL 小于等于
NOT_EQUAL 不等于
(2)比较器
BinaryComparator 匹配完整字节数组
BinaryPrefixComparator 匹配字节数组前缀
RegexStringComparator 正则表达式匹配
SubstringComparator 子串匹配
# FILTER。组合过滤器,多个过滤器可以通过ANDOR连接进行组合过滤。表示列名以e或者m开头,并且英文的分数中包含了9的列。
scan 'student', {FILTER => "(MultipleColumnPrefixFilter('e','m')) AND (SingleColumnValueFilter('course','english',=,'substring:9'))"}
参考资料