Group By是一种常用的操作,用于对数据进行分组并对每个分组进行聚合计算。
MapReduce模型
- Map阶段: 在Group By操作中,Map阶段的任务是将输入数据进行拆分并映射到不同的Reduce任务上。Hive将输入数据根据Group By的字段进行分组,并将每个分组的键值对发送给对应的Reduce任务。在Map阶段,还可以执行一些预聚合操作,如计算每个分组的局部聚合结果,以减少后续Reduce阶段的数据量。
- Shuffle和Sort阶段: Shuffle和Sort阶段是MapReduce的核心阶段之一。在Group By操作中,Shuffle阶段负责将Map阶段输出的键值对按照分组键进行排序,并将同一分组的键值对合并到同一个Reduce任务上。这样,具有相同分组键的数据就被发送到了同一个Reduce任务上,方便后续的聚合计算。
- Reduce阶段: Reduce阶段是执行实际的聚合计算的阶段。每个Reduce任务处理一个或多个分组的数据,并对每个分组进行聚合操作,如计算Sum、Count、Avg等聚合函数。Reduce任务会接收来自Shuffle阶段的数据,对每个分组进行聚合,并输出最终的聚合结果。
- Combiner优化: 为了进一步提高性能,Hive还支持Combiner优化。Combiner是在Map端执行的部分聚合操作,可以减少Shuffle阶段传输的数据量。如果在Hive查询中启用了Combiner优化,并且聚合函数满足结合律和可交换律,Hive会尝试在Map端对数据进行局部聚合,以减少数据传输和Shuffle阶段的工作量。
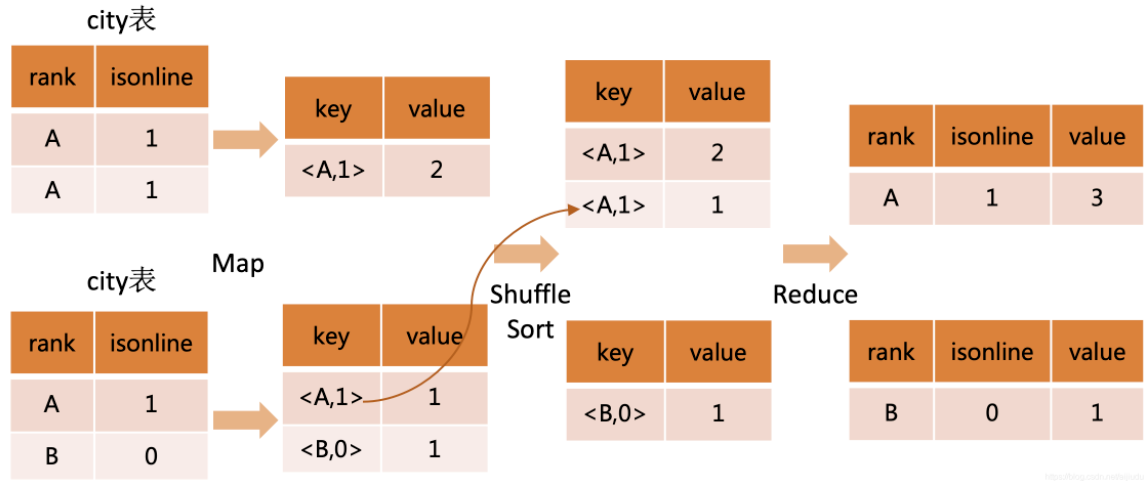
实际案例流程
hive 默认设置了hive.map.aggr=true,会在mapper端先group by一次,最后把结果merge起来,为了减少reducer处理的数据量。
select rank, isonline, count(*) from city group by rank, isonline;- 在 map 端,将group by的字段作为输出的key,存入环形缓冲区,排序写入本地文件,然后做一次本地group by即combiner。
- 在 map 端,输出的value视情况而定:如果是count,则value是1;如果是sum,则value是对应的值。
- 在 reduce 端,拉取对应的分组数据,写入环形缓冲区,排序写入本地文件。
- 在 reduce 端,将组内的数据聚合,然输出结果。